
# TL;DR
BigQuery のクエリの調査は以下のようにすると良い。
- 一部のクエリが大量のデータを処理していないかを、BigQuery の Monitoring で調べる。
- 原因になってそうな JOB_ID が特定できたら、INFORMATION_SCHEMA.JOBS を見て調べる。
- 容量を食っているテーブルを調べたい場合は、INFORMATION_SCHEMA.TABLE_STORAGE を調べる。
- ログを追いたい場合は Cloud Logging を見る。
# 問題の発見
発端は BigQuery の課金額が 1 万円を超えるという報告が飛んできたことです。
弊社では数 GB 程度のテーブルが数十ありそれを日々様々なスケジュールドクエリなどで捌いていますが、それでも突然 1 万円を超えるのはおかしい…🤔 と怪しく思いました。BigQuery の課金はスキャン 1TB あたり $5 程度なので、1 万円というのはペタバイト級のデータを処理しないと発生しない額です。
ということで何が原因なのかを調べる際に便利な情報をまとめます。
# BigQuery の請求モニタ
BigQuery の管理画面の Monitoring から、BigQuery がどのように利用されているかを調べることができます。
Location で Tokyo を選択し、グラフの設定で Chart を Bytes Processed 、Group by を Job にすれば、ジョブごとに処理されたデータの容量をグラフにプロットできます。
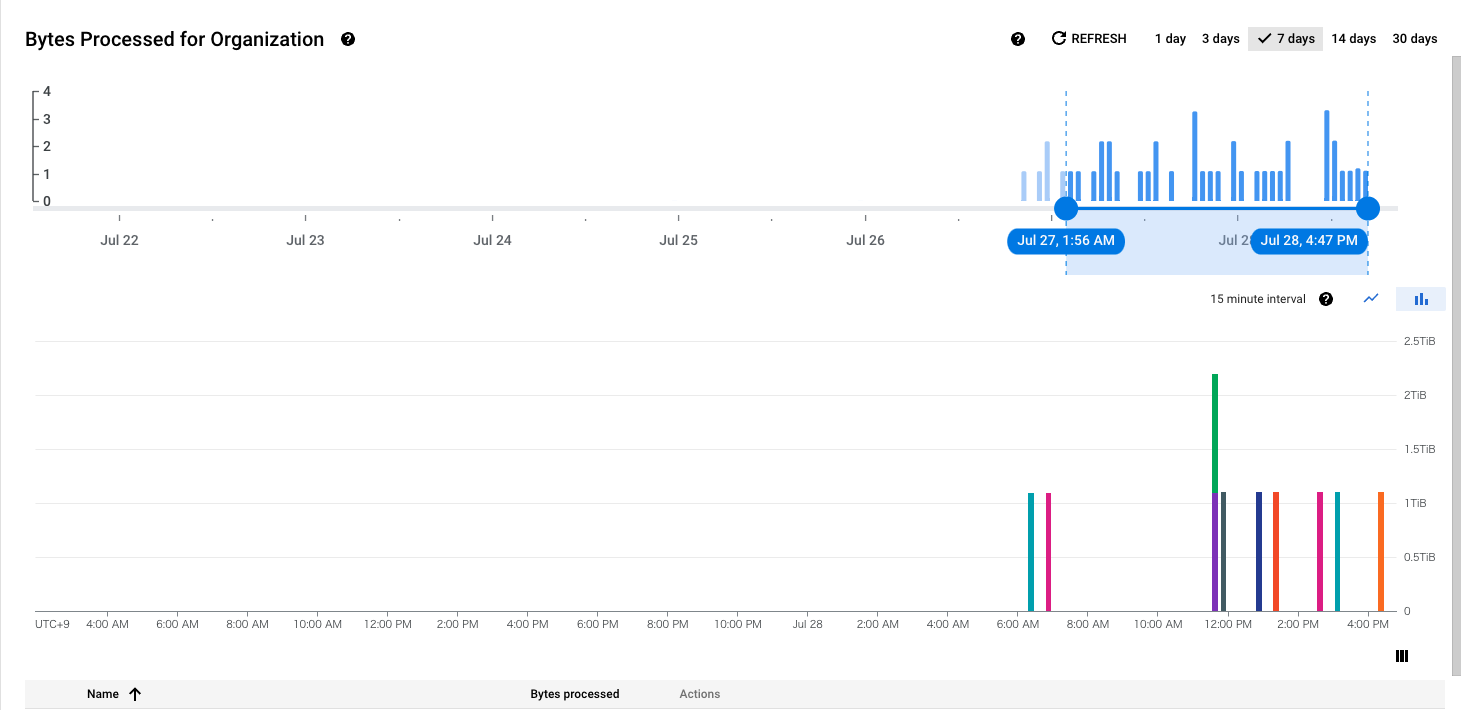
一番下に表があり、そちらにクエリの名前と処理データ量が表示されます。ここで、スケジュールドクエリは [PROJECT_ID]:scheduled_query_[JOB_ID] のような形式らしいのでここからスキャンの大きいクエリの JOB_ID を調べてメモしておきます。
今回のケースでは、結論から言ってしまうととても重い一部のクエリが 1 日に何度も発行されるがそれ以外のクエリはめちゃくちゃ軽いという極端なケースなので、グラフもスパイクが見られる形になっています。
(表の Actions からジョブの詳細を見るメニューがありますがそれは押しても何も起きませんでした。なぜ?)
# Cloud Logging を使ったクエリの特定
次に、先ほどメモしたクエリの内容を調べます。BigQuery ではこれ以上の詳細はわからなさそうだったので、Cloud Logging 上でこのクエリについて検索をかけます。 Logs Explorer にて例えば以下のような検索クエリを実行します。
resource.type="bigquery_resource"
protoPayload.serviceName="bigquery.googleapis.com"
protoPayload.methodName="jobservice.insert"
protoPayload.serviceData.jobInsertRequest.resource.jobConfiguration.labels.dts_run_id=[JOB_ID]
すると、次のような結果が 1 件ヒットしました。
{
insertId: "-xxxxxxxx"
logName: "projects/[PROJECT_ID]/logs/cloudaudit.googleapis.com%2Fdata_access"
protoPayload: {10}
receiveTimestamp: "2022-07-27T23:35:03.788379164Z"
resource: {2}
severity: "INFO"
timestamp: "2022-07-27T23:35:03.711793Z"
}
これの中にクエリについての詳細な情報が入っています。例としては、
protoPayload.authenticationInfo: このジョブを実行したのが誰の権限によるものかprotoPayload.serviceData.jobInsertRequest.resource.jobConfiguration.query: このジョブで発行されたクエリに関する情報.query: 発行された SQL
protoPayload.serviceData.jobInsertRequest.resource.jobName.jobId: さきほど指定した JOB_ID が入っている
などを見ることができます。
しかし、Cloud Logging ではステータスが RUNNING のログしか見つからなかったため(それともログの出力の仕方がそもそもそういうものなのかもしれませんが?)、ここでは実際に何 byte のデータをスキャンしたのかはわかりませんでした。
エラーのログなどは確認できるので、エラーの詳細などを追いかけたい場合はこれを見るのが良さそうです。
# INFORMATION_SCHEMA を使った調査
さて、これまでの JOB に関する検索は、BigQuery の INFORMATION_SCHEMA を使っても同様のデータを見ることができます。
参考:
上記ページを参考に、JOB を検索してみます。
select * from [PROJECT_ID].`region-asia-northeast1`.INFORMATION_SCHEMA.JOBS where job_id = [JOB_ID] limit 1;
結果の total_bytes_processed を見ることで、このジョブでどのくらいのデータがスキャンされたかがわかりました。
これにより、実際にこのジョブで発行されたクエリが課金の原因であることがわかりました。一方で、クエリ自体は単純な JOIN をしているだけであったので、いずれかのテーブルが重すぎるのではないかと睨みました。
INFORMATION_SCHEMA からテーブルのストレージ容量を調べることもできるので、そちらも同様に見てみます。
参考:
select * from [PROJECT_ID].`region-asia-northeast1`.INFORMATION_SCHEMA.TABLE_STORAGE order by active_logical_bytes desc;
これにより、容量が多い順にプロジェクト内の全てのテーブルを並べ替えることができました。
実際にはここに 1TB 以上のテーブルが存在していることがわかり、課金が発生した原因となったテーブルを特定できました。
# まとめ
BigQuery のログなどを追うことがあまりなかったので学びがあった。